Datasets Harmonization
Schema Merging Overview
When working with multiple datasets that share similar structures but have slight variations in their schemas, it is essential to harmonize these schemas to enable seamless querying and analysis. Schema harmonization involves aligning the schemas of different datasets to create a unified view. Beacon provides robust support for schema harmonization, allowing users to query multiple datasets with differing schemas as if they were a single cohesive dataset. This is particularly useful when dealing with datasets that may have evolved over time or have been collected from different sources.
How Schema Harmonization Works
Beacon employs a schema merging strategy that intelligently combines the schemas of multiple datasets. The key steps involved in this process are as follows:
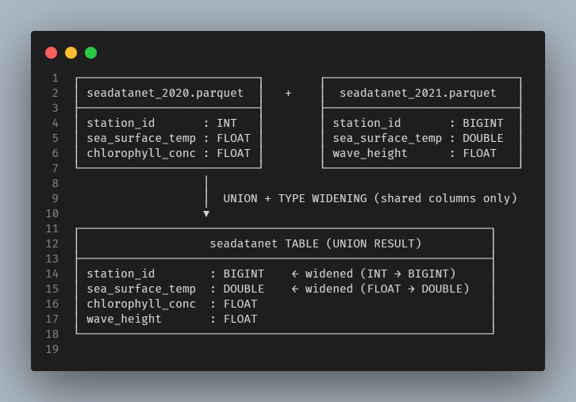
- Schema Extraction: Beacon extracts the schema from each dataset, identifying the fields, data types, and structures present in each dataset.
- Field Alignment: Beacon aligns fields across datasets based on their names and data types. If fields with the same name have different data types, Beacon will attempt to find a common data type that can accommodate all variations.
- Handling Missing Fields: If a field is present in one dataset but missing in another, Beacon will include the field in the merged schema and fill in missing values with nulls or default values as appropriate.
- Conflict Resolution: In cases where there are conflicts in field definitions (e.g., different data types for the same field), Beacon applies predefined rules to resolve these conflicts, such as promoting to a more general data type.
N-Dimensional Datasets Harmonization
Beacon also supports harmonization of n-dimensional data, which is common in scientific datasets such as Zarr & NetCDF files.
When merging n-dimensional datasets, Beacon will flatten the file based on the variables selected in the query using Broadcasting similar to Numpy or other array programming libraries.
Once the datasets are flattened, Beacon will perform schema merging on the resulting tabular data as described above.